Can OpenACC Simplify FPGA programming?
OpenACC has provided a high-level option for GPU programmers for years. Application developers interested in GPU-accelerated performance without the details, complications, and overhead of programming in a language, such as CUDA, have found OpenACC to be an attractive solution. However, OpenACC's potential as an efficient option for other types of accelerators, such as Field Programmable Gate Arrays (FPGAs), is still under exploration. A research team with collaborators from the University of Oregon and Oak Ridge National Laboratory is investigating this exact question with the development of their OpenACC-to-FPGA framework.
Moving to HLS
Traditionally, FPGAs have been programmed using Hardware Definition Languages (HDLs) such as Verilog and VHDL. These approaches enable the customized development of hardware logic, fully harnessing the FPGA's reconfigurable nature. However for most HPC application developers and scientific programmers, the complexity of HDLs created a barrier for FPGAs as hardware accelerators.
More recently, FPGA vendors such as Intel and Xilinx have invested in the development of High-Level Synthesis (HLS) tools as an alternative to HDLs for FPGA program design. These tools synthesize OpenCL or C++ as a source, automatically generating the lower level design layout mapped to the FPGA device. OpenCL, with an abstraction level similar to CUDA. The HLS approach is typically far more palpable to HPC developers and scientific programmers than HDL approaches (that require in-depth knowledge of digital logic, circuit timing, etc.). However, the OpenACC-to-FPGA team still sees two major drawbacks to the OpenCL HLS approach:
1) The HLS OpenCL abstraction level is too high for FPGA programming.
FPGAs are attractive accelerators because of their customization potential. Shift registers, hardware channels, and pipelined execution produce extremely efficient designs for certain applications. However, standardized OpenCL does not provide natural ways to express these customizations. As a result, expressing these features in HLS OpenCL applications often requires complex programming patterns and FPGA-specific keywords, API calls, and directives. In short, the OpenCL abstraction level is too far removed from HDLs to naturally program desirable customizations in FPGAs.
2) The HLS OpenCL abstraction level is still too low for scientific programming.
The success of OpenACC and OpenMP demonstrates that the abstraction level of CUDA and OpenCL is still too low for many application developers. In the case of HLS OpenCL for FPGAs, this problem is exacerbated by the unnatural FPGA-specific programming discussed above.
Leveraging OpenACC for FPGA Programming
To address these two shortcomings of HLS OpenCL programming for FPGAs, the team developed the OpenACC-to-FPGA framework, built on top of the prototyping OpenACC compiler, OpenARC. In developing the framework, OpenARC was modified to accept OpenACC applications as input, and generate HLS OpenCL for FPGAs as output. This output is then redirected and synthesized by an HLS tool, such as the Intel FPGA SDK for OpenCL. The team's main question: Can OpenACC in its current state be a realistic option for FPGA programming? The team's answer: yes, and no.
Yes: In the same way that OpenACC abstracts GPU-specific behavior compared to CUDA, such as kernel instantiation, host and device memory behavior, etc., OpenACC can abstract FPGA-specific behavior present in HLS OpenCL. Desired FPGA behavior such as dynamic memory transfer alignment and kernel boundary check elimination can be automated by an OpenACC compiler. Also, many FPGA customizations that require an unnatural complex programming pattern in HLS OpenCL can be naturally expressed in OpenACC using existing directives. An OpenACC compiler can generate FPGA-specific reductions, FPGA-specific loop collapsing, and FPGA-specific pipeline parallelism using the existing OpenACC reduction, collapse, and kernel dimension clauses, with the application developer potentially unaware that they are generating FPGA-specific code. These capabilities were precisely targeted and developed in the OpenACC-to-FPGA framework.

No: Certain FPGA customizations have no natural abstraction even at the OpenACC level. Features like sliding windows, channel pipelining, and compute unit replication are foreign concepts in the OpenACC standard. However, the team is still moving forward with these FPGA customizations at the OpenACC level by introducing and implementing novel directive extensions in the OpenACC-to-FPGA framework, made possible by the prototyping OpenARC compiler. These extensions include a window directive, a channels directive, and two replication directives. In the OpenACC spirit, these directives provide programmers with a simple and natural way to express FPGA customizations, as opposed to the more complicated HLS OpenCL patterns. If the interest in FPGAs as accelerators in scientific continues to grow, and OpenACC continues to be explored as a programming option, the team hopes these extensions may become candidates for inclusion in the OpenACC standard. So no, OpenACC in its current state is not enough for FPGA programming, but it may be at some point in the future.

The first code example shows HLS OpenCL with FPGA-specific programming patterns for customizations.
The second code example shows analogous OpenACC input that can be used to generate the same FPGA-specific customizations as the HLS OpenCL example, using the OpenACC-to-FPGA framework.
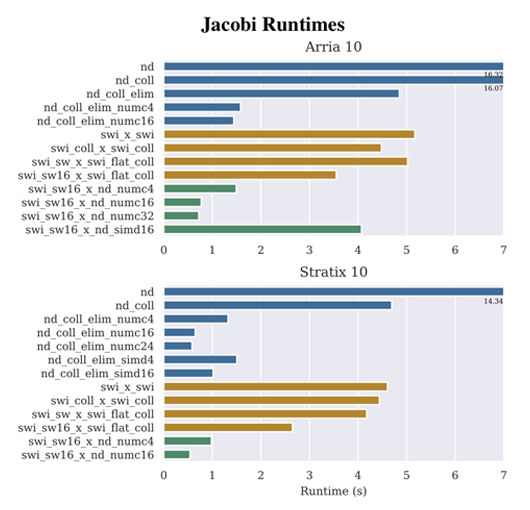
The figure shows the improvements in performance realized by applying the FPGA-specific optimizations developed in the OpenACC-to-FPGA framework on a Jacobi kernel using two FPGAs: an Intel Arria 10 (top graph) and an Intel Stratix 10 (bottom graph). The OpenACC-to-FPGA framework highlights three different execution modes in the figure: multi-threaded kernels (nd, blue bars), single-threaded pipelined kernels (swi, orange bars), and hybrid applications that contain both single-threaded and multi-threaded kernels (green bars). Within each mode, additional FPGA-specific optimizations can be applied, abbreviated in the labels as coll for loop collapsing, numc for compute unit replication, etc. Generally, as we apply more optimizations within the framework we see increased performance, indicated in the figure by lower runtimes and smaller bars. To read more about these optimizations and their applications, see the full paper linked below.
Final Thoughts
While the power of HDLs may never be realized at the abstraction level of OpenACC, the University of Oregon and Oak Ridge National Laboratory team plans to continue investigating OpenACC as a promising option for high-performance FPGA-accelerated scientific code. The team plans to continue development of the OpenACC-to-FPGA framework to include more FPGA-specific customizations while maintaining the OpenACC spirit of natural and simple programming.
Author
